DL M14: Embeddings (Meta)
Module 14 of CS 7643 - Deep Learning @ Georgia Tech.
Introduction
Embeddings map objects to vectors via some trainable function. In the context of deep learning, we typically frame embeddings as follows:
- Learning Problem: derive some informative embedded feature space $d$ such that mapping inputs from the original feature space $p$ produces informative representations of the original instances.
- Trainable Function: train a neural network to learn this mapping, as to maximize some objective function.
- ex: autoencoders and mean squared error between original : reconstructed instances.
We have seen embeddings applied within the context of certain task domains, especially in the field of natural language processing. In this lesson, we will build on concepts explored in previous lessons and explore other applications of embeddings.
Word Embeddings
Word Embeddings seek to find some informative representation of individual words, typically based on word context. Most algorithms frame word embeddings in terms of Distributional Semantics, such that we approximate a word’s semantic meaning based on the words that tend to surround it. This turns out to be an extremely successful idea!
Recall that a word’s context refers to the set of words that appear nearby within some fixed-size window. Given a word $w$ and many contexts $x_i$, we can effectively train a neural network to understand the context (proxy for meaning) of the word.
Neural Word Embeddings
Research on using neural networks to define word representations kicked off in the early 2000s. In 2013, word2vec was introduced as an efficient estimation of word representations in vector space. The original paper provided two versions of word2vec:
- Continuous Bag-of-Words (CBOW): predict a word in context, given surrounding words.
- Skip-Gram: predict the context words, given a single word (see image below).
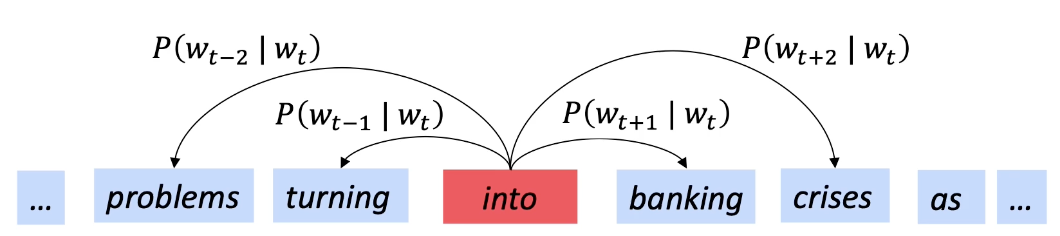
Other neural word embedding techniques include…
- GloVe (Global Vectors): model trained on global word-to-word cooccurrence statistics.
- fastText: generates sub-word embeddings, which better handles out-of-vocabulary words.
Once we have word embeddings, a common application is to use them as input features for NLP tasks such as text generation.
Evaluation
Given a word embedding, how can we evaluate its quality? One common strategy is to perform some analogical reasoning using the embeddings. For example, we would expect a “good” word embedding system to map words with similar meaning to similar representations.
We can test this concept by computing relationships of the form a:b :: c:?. The classical example is man:woman :: king:? $\rightarrow$ what word has a similar distance from king, as the distance from man to woman, in the embedded feature space? We first solve for our target embedding, then compute Cosine Similarity between this embedding and all embeddings in our vocabulary.
- Step 1: Solve for target embedding.
- Step 2: Identify embedding with maximal cosine similarity to target embedding.
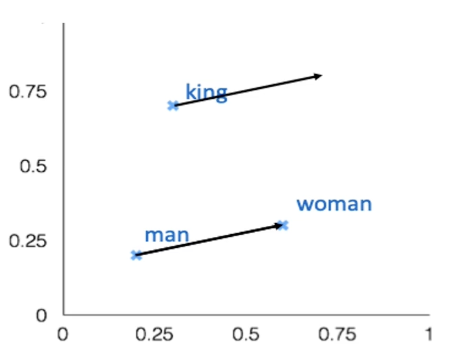
If our embedding system is good, we would expect semantically reasonable words to correspond to the target embedding(s) produced by this system (ex: in the above example, “queen”).
Graph Embeddings
In computer science, a Graph refers to a structured network of interconnected nodes, where connections are referred to as edges.
- Nodes: represent some entity (individual object / instance).
- Edges: represent relationships between entities; may be directed.
Examples applications of graphs include…
- Knowledge Graphs: contain knowledge by representing all (known) relationships between all (known) entities. Most common structure for studying graph embeddings.
- Recommender Systems: use graph-like data framed in a supervised learning problem.
Recall that an embedding is a learned map from entities to vectors, where the transformed feature space should encode some notion of similarity between entities. Graph Embeddings optimize the objective that connected nodes should have more similar embeddings as compared to unconnected nodes. Features can be used as task-agnostic entity representations, and tend to be useful for downstream tasks with limited data.
Model Training
Given a graph, our dataset will consist of a set of edges $E$ defining relationships $r$ between entities. We can artificially construct negative instances by taking a real edge and replacing the source $s$ / destination $d$ with a random node (with the constraint that the node is not related to its corresponding source / destination in our dataset).
With this data, our objective is to maximize the margin loss between the score for an edge $f(e)$ and a negative sampled edge $f(e’)$.
\[\mathcal{L} = \sum_{e \in E} \sum_{e' \in E'} \max [f(x) - f(e') + \lambda, 0)]\] \[f(e) = \cos(\theta_s, \theta_r + \theta_d)\]Applications of Graph Embeddings
We can use a set of graph embeddings for various applications, such as embedding a knowledge base. Embedded knowledge bases are useful for tasks such as question answering, where we can perform lookup by maximizing cosine similarity between an embedding of our query $q$ and embeddings int he graph $g \in G$.
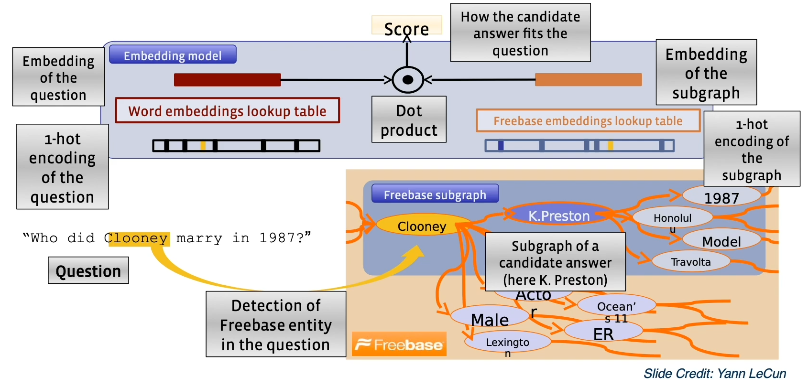
Other Applications
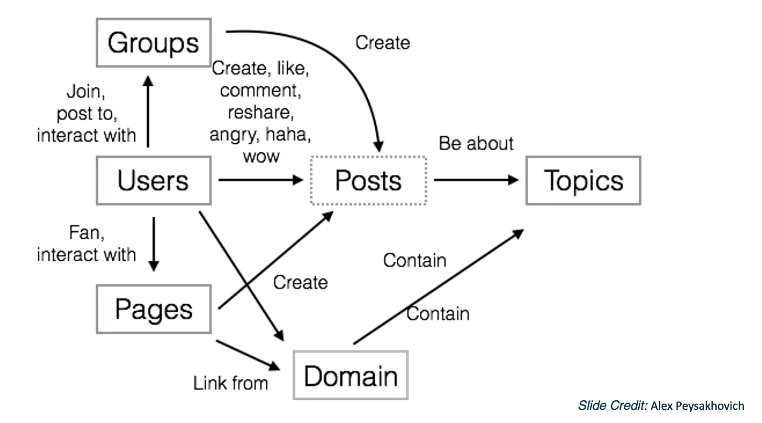
Facebook “Spaces”
TagSpace defines tags (hashtags) for unlabeled text (user posts). This is particularly useful for categorization of social media posts, especially in terms of user reviews. TagSpace first generates word embeddings for both post text and hashtags, then uses these learned embeddings for labeling. The final set of labeled posts can then be analyzed in terms of the tags (ex: clustering of hashtags).
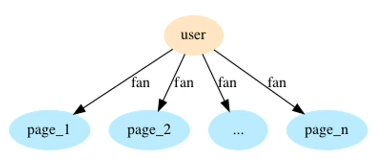
PageSpace takes (user, page) pairs from Facebook to recommend pages to users. PageSpace generates graph embeddings for for users and pages, then identifies potential recommendations by “filling in the gaps.” PageSpace can also be used to define clusters of pages.
Finally, VideoSpace is a Facebook system which generates page embeddings, video embeddings (via CNN), and word embeddings as features for downstream classification + recommendation tasks.
world2vec
As evident from the definition of VideoSpace, we can generate embeddings for a wide range of entities to use as part of downstream tasks. What if we generalize “wide range of entities” to literally any object in the world? world2vec is a Facebook system which attempts to incorporate this paradigm, where “all entities in the world” is defined relative to Facebook.
After creating embeddings, they can be used in combination with other features for a number of downstream tasks.
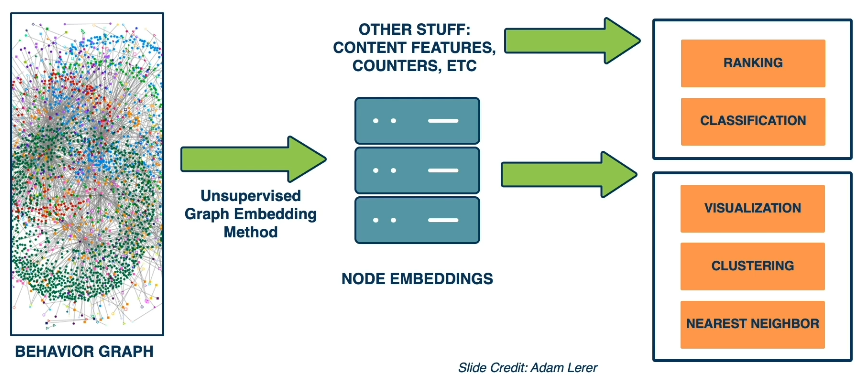
Note that the size of something like a Behavior Graph is MASSIVE. This can result in computational issues when performing embedding in combination with machine learning techniques. As opposed to using all graph data, Facebook uses Matrix Blocking to subdivide the graph into shards. Then, the full ML system may be trained via distributed training, or on subregions of the graph relevant to the task at hand.
Additional Topics
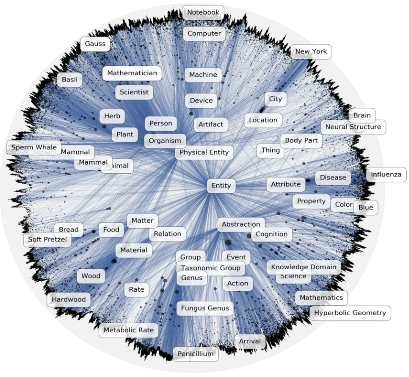
Hierarchical Embeddings
Hierarchical Embeddings are a newer class of embedding methods which learn hierarchical representations by embedding entities into hyperbolic space. This results in an embedding space which contains more general entities closer to the center, and more specific entities further from the center.
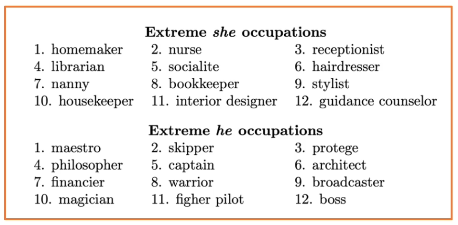
Bias in Word Embeddings
As we create systems that increasingly rely on word embeddings, we should be careful to account for any potential issues regarding bias and fairness. Any word embedding model will define “meaning” relative to the data it is trained on. Therefore, any patterns (desired or not) in the training data will be incorporated into the embedding strategy.
This can be problematic in a number of ways. For example, gendered language patterns can amplify existing discriminatory and unfair behaviors.
“Man is to Computer Programmer as Woman is to Homemaker?”
Debiasing is a technique which attempts to remove bias from an embedding system. However, bias is pervasive + difficult to remove, so debiasing efforts are typically not very effective. There is a growing body of research on debiasing, so we might expect advancements in the near future.
Bias will be covered in an upcoming lecture - more detail on concepts + research will be provided then.
(all images obtained from Georgia Tech DL course materials)