DL M15: Scalable Training
Module 15 of CS 7643 - Deep Learning @ Georgia Tech.
Overview
Modern deep learning libraries such as torch provide direct integration with the Graphics Processing Unit (GPU) to drastically increase computational efficiency via parallelization. Whenever possible, we should prefer torch operations over base Python to benefit from this enhanced efficiency.
Script Mode
Additionally, torch has different modes depending on the level of desired optimization:
- Eager Mode: default mode which executes code line-by-line. Useful for model development and prototyping.
- Script Mode (TorchScript): converts models to programs via Just-in-Time (JIT) interpreter, with programs being optimized for production runtimes.
We can convert normal functions to programs optimized by JIT using torch.jit.script. For example…
1
2
3
4
5
6
7
8
9
10
11
12
a = torch.rand(5)
def func(x):
for i in range(10):
x = x*x
return x
scripted_func = torch.jit.script(func)
%timeit func(a)
# 18.5 microseconds per loop
%timeit scripted_func(a)
# 4.41 microseconds per loop
JIT performs various types of optimization to increase efficiency.

End-to-End Scalable Training
Ingesting Data
How can we efficiently load + use data as part of our machine learning workflow? PyTorch provides the following classes to interact with data:
- Dataset: construct representing our data. Supports operations such as iteration and mapping.
- Data Loader: enables batching and parallelization, which is very helpful during model training.
1
2
3
4
5
6
7
8
9
from torch.utils.data import DataLoader, RandomSampler
dataloader = DataLoader(
dataset, # only for map-style dataset
batch_size=8, # balance speed and convergence
num_workers=2, # non-blocking when > 0
sampler=RandomSampler,
pin_memory=True
)
Pinned memory (also known as page-locked memory) refers to a specific hardware optimization concept for transferring data from the CPU to the GPU. Normal RAM is pageable, meaning it is separated into bocks called pages that can be swapped out to the disk as needed. In contrast, pinned memory is page-locked such that the operating system cannot swap it to disk. Before CUDA can send data from CPU to GPU, it must first create a page-locked version of the data. In the case of pinned_memory=True, torch loads the data into page-locked memory to avoid the expensive copy operation when sending to GPU.
For a more thorough overview of pinned memory, check out the PyTorch guide.
Distributed Computing
We have primarily discussed Parallelism in terms of the operations performed by a single GPU. In this section, we will extend our discussion of parallelism to include distributed computing, whether in terms of multiple GPUs on a single machine or multiple machines.
In deep learning, we frame distributed parallelism from two major perspectives:
- Data Parallelism: data is distributed across devices.
model = torch.nn.DataParallel(model) - Model Parallelism: model is distributed across devices. Intended for cases where the model itself is too large to fit on a single machine.
- must manually set layers to corresponding device in network
__init__function, and manually transfer data to device inforwardfunction.
- must manually set layers to corresponding device in network
Here are a few examples of parallelized implementations:
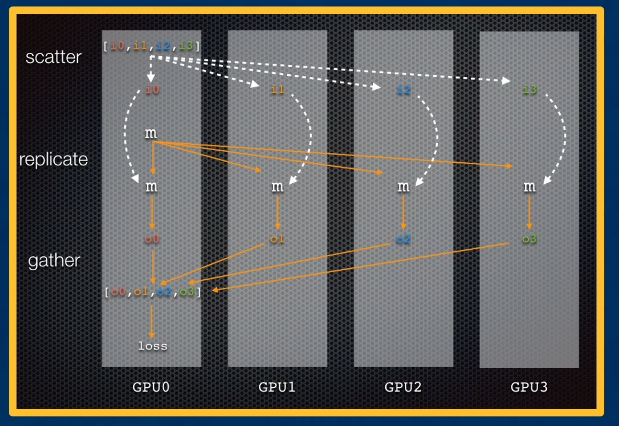
- Single Machine Data Parallel: data is scattered across GPUs, and model is replicated on each GPU.
torchtakes care of gathering the data on each GPU to compute loss, then updating the parameters across GPUs.
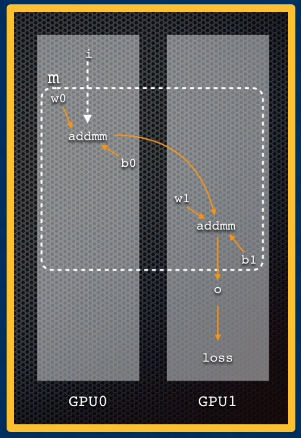
- Single Machine Model Parallel: model is shared across GPUs. An instance is sent through a portion of the model, and the intermediate activation is transferred to the next device to proceed as dependent on model distribution architecture.
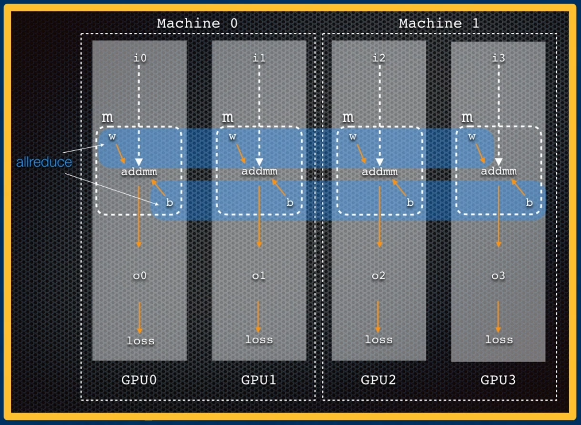
- Distributed Data Parallel: each GPU across machines receives different instances to process.
torchmust account for parameter updates performed across multiple GPUs / machines; this is done withinloss.backward().
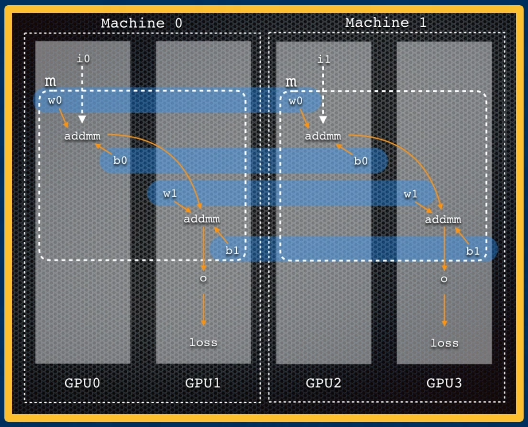
- Distributed Data Parallel with Single Machine Model Parallel: combines concepts of distributed data parallel - data processed across multiple machines - with single machine model parallel - model distributed across multiple GPUs on same machine. Model is replicated on each machine.
- Distributed Model Parallel: model is shared across GPUs on multiple different machines.
- Distributed model parallelism in PyTorch makes use of Remote Procedure Call (RPC) via
torch.distributed.rpc. Recall that RPC is a method for calling a function locally, but having the function execute on a remote machine. - Distributed autograd and distributed optimizer extend
torchmodel training methods across multiple machines. For example, Hogwild! is a distributed optimizer which implements stochastic gradient descent (SGD) across machines in a non-locking fashion. In other words, each machine can perform parameter updates without a locking mechanism.
- Distributed model parallelism in PyTorch makes use of Remote Procedure Call (RPC) via
(all images obtained from Georgia Tech DL course materials)