DL M16: Responsible AI
Module 16 of CS 7643 - Deep Learning @ Georgia Tech.
Introduction
Responsible AI refers to a set of principles that guide the development / application of AI solutions by considering their broader societal impacts. In this lesson, we will define various responsible AI components, and discuss potential issues / responsibilities relevant to the work of AI practitioners.
Concepts in Responsible AI
Bias, Fairness, and Equity
Recall that we’ve discussed bias in terms of the bias-variance tradeoff when constructing a model:
- Machine Learning Bias: assumptions made by the specific modeling approach for representing a problem, that tend to limit the representational flexibility of a model.
- Machine Learning Variance: ability for the model to change relative to slight perturbations in the input. Results from increasing the representational flexibility of a model (whether via general modeling approach or increased parameterization).
From the perspective of responsible AI, bias is defined as any systematic preference (fair or unfair) relative to a particular group. For example, gender biases are commonly found in word embeddings.

Fairness refers to impartial treatment / behavior without preference to a particular group. Similarly, equity is the quality of being fair and just. In responsible AI, there are multiple criteria which may define fairness in a system. For example, is our system fair with respect to gender? What about age?
Provenance, Validation, Robustness, and Resilience
Provenance refers to the documented history / origin of an instance - in machine learning, provenance is used to describe the origins of your data and its usage. It is particularly important for audibility and explainability relative to highly complex / distributed AI systems.
AI systems are validated to ensure they perform as designed. In classical software development, validation is performed via methods such as unit tests or penetration tests. AI systems are validated in terms of data splitting (for model evaluation) and adversarial approaches (penetration testing intended to test whether a machine learning model produces undesirable results).
Our goal is to build robust and resilient ML systems:
- Robust $\rightarrow$ reliable + secure.
- Resilient $\rightarrow$ ability to adapt to risk.
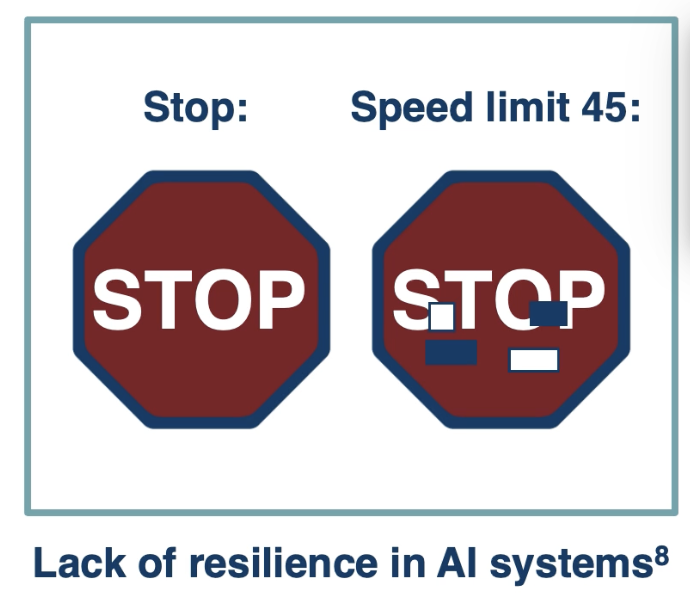
Adversarial examples are often used to test a system’s resilience. For example, does the system perform predictably when faced with novel (adversarial) situations, or produce undesirable results?
Safety, Security, and Privacy
Safety is a domain-specific concept in AI. For example, a system which classifies images as hotdog vs. not hotdog has a much different perspective on safety as compared to one for self-driving cars. We design audit systems for evaluating potential safety issues and sources of harm relative to a given AI system:
- Failure Modes and Effect Analysis (FMEA): what could go wrong and how?
- Fault Tree Analysis (FTA): what conditions lead to failure modes?
Many security paradigms from other fields of software development (e.g. cybersecurity) still apply in the context of AI. For example, we may want our system to encrypt data in transit, have a user authentication component, and limit access to certain individuals. In addition to these general components, AI systems are unique and thus have security concerns specific to the system:
- Poisoned Training Data: adversaries may infect model training data with purposefully altered instances, causing the model to learn some undesired pattern.
- Model Evasion: tampering with instances at inference time may cause a model to produce specific undesirable results (ex: stop sign from previous section).
- Data Gleaning: individuals may be able to exfiltrate data / information from a model, either via access to model data or inference from model predictions.
Privacy is particularly relevant to the last point. As part of privacy, our AI system should ensure that subject data remains private (whether in terms of development and inference). There are many simple approaches to privacy in AI:
- De-Identify Instances: remove names / identifiers from instances. Challenge is that re-identification is often trivial.
- Generalize Fields: reduce granularity of information to better anonymize records (ex: 56 $\rightarrow$ $<$ 60). Challenge is that individual records will still exist.
One modern approach to private AI is differential privacy, which adds noise during the model training process (e.g., stochastic gradient descent) to make re-identification impossible. Another approach - federated learning - involves splitting the data and model between a model owner (e.g., server) and data subject (e.g., end-user device).
Transparency, Interpretability, and Explainability
Transparency in machine learning refers to understanding how and why a model arrived at a certain prediction. Transparency might include the type of data used for model training, the model’s intent, and the recency of model training. Transparency poses unique challenges, including competitive considerations and a robustness / safety tradeoff.
The more an adversary knows, the more they can use that knowledge in attacks.
Model interpretability is a related concept which involves understanding how an AI system works. Interpretability generally asks questions at the model / system level:
- Which features are important?
- What is the magnitude of importance?
Explainability is similar to interpretability, but asks questions at the instance level (ex: SHAP).
Empowerment, Redress, Accountability, and Governance
Empowerment in AI systems refers to educating users about usage of AI, and providing users with control when interacting with AI systems. Redress is a related concept describing “relief from distress” - in the context of machine learning, this involves providing users with means of rectifying harm.
Finally, AI systems themselves cannot be held accountable, but the organizations and people deploying these systems can. Governance is the process for ensuring accountability, compliance, and ethical decision making when building AI systems.
Bias and Fairness
Calibration and the Fairness Impossibility Theorems
A classifier is considered calibrated if the probability of the observations with a given probability score of having a label is equal to the proportion of observations having that label.
- Example: if a binary classifier assigns a score of 0.8 to 100 observations, then 80 of those observations should have a true label of the positive class.
- Note that the probability below is equivalent to Positive Predictive Value (PPV) for a particular score!
In terms of bias and fairness, we are more interested in group calibration - the scores for subgroups of interest should be equally calibrated.
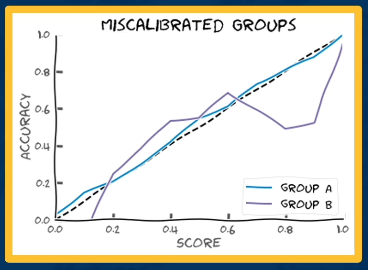
So how can we calibrate a deep learning model? Platt scaling is a post-processing approach which uses an additional validation set to learn parameters such that the calibrated probability is a function of the network’s output (logits).
- Platt Scaling: Binary Classifier
- Plat Scaling: Multi-Class Classifier (must use Temperature scaling)
The Fairness Impossibility Theorems refer to any theorem obtained via three (or more) measures of model performance derived from the confusion matrix.
\[p = \frac{TP + FN}{TP + FP + TN + FN}\]It is impossible for a classifier to achieve both equal calibration and error rates between groups, if there is a difference in prevalence between the groups and the classifier is not perfect.
In a system of equations with three of more equations, $p$ is determined uniquely. If groups have different prevalence, these quantities cannot be equal.
FAT Problems
Fairness, Accountability, and Transparency (FAT) refers to a group of related problems in responsible AI. What can we do to prevent FAT problems?
First, we establish ethical frameworks to conduct research / AI implementation in an approved fashion (e.g., Belmont Report for research). For example, the Markkula Center Framework for Ethical Decision-Making defines a reasonable ethical framework:

The “approaches” (step 3) refer to academic philosophical schools that offer broadly different perspectives focusing on different aspects of the problem.
One of the most common examples of a FAT problem is gender bias in word embeddings. Recall that word embeddings represent words as vectors derived from their co-occurrence matrix (e.g., word2vec, GloVE). In previous lectures, we discussed the idea of analogies for word embeddings - we can calculate the difference between two words, and use it to solve for the analogous answer relative to a query term. For example…
\[\text{man} : \text{woman} ~~~ : ~~~ \text{king} : \text{?} ~~ \rightarrow \text{queen}\]While this example is reasonable, other examples reveal biases based on gender:
\[\text{he} : \text{she} ~~~ : ~~~ \text{surgeon} : \text{nurse}\]Therefore, suggestions have been made to reduce embedding bias via debiasing.
Privacy Regulations
The current (early 2020s) consumer privacy / AI regulation landscape involves…
- General Data Protection Regulation (GDPR): EU regulation setting forth rules regarding how companies treat personal data of consumers. The primary goal of GDPR is to enhance individuals’ control and rights over their personal information.
- California Consumer Privacy Act (CCPA): one of the broadest online privacy laws in the United States. The primary goal of CCPA is to enhance privacy rights and consumer protection for residents of California.
- In 2019, bills to regulate user privacy on the internet were filed or introduced in at least 25 US states.
As we build AI systems, it is important to consider privacy - the use of any consumer data is likely subject to regulations. For example, Facebook was sued by the FTC in 2012 for eight separate privacy violations pertaining to face recognition.
(all images obtained from Georgia Tech DL course materials)