DL M19: Translation and ASR (Meta)
Module 16 of CS 7643 - Deep Learning @ Georgia Tech.
Translation at Meta
At the time of this lecture, Meta provided over 6 billion translations per day across different products such as Facebook, Messenger, Instagram, etc. The general translation framework used at Meta works as follows:
- Language Identification: given content (ex: post), classify the text in the content as a particular language.
- User Language Prediction: given the user (and historical data), predict which language the user is most likely to prefer to view the content in.
- If the content language and user-predicted language do not match, present “view translation” button to the user.
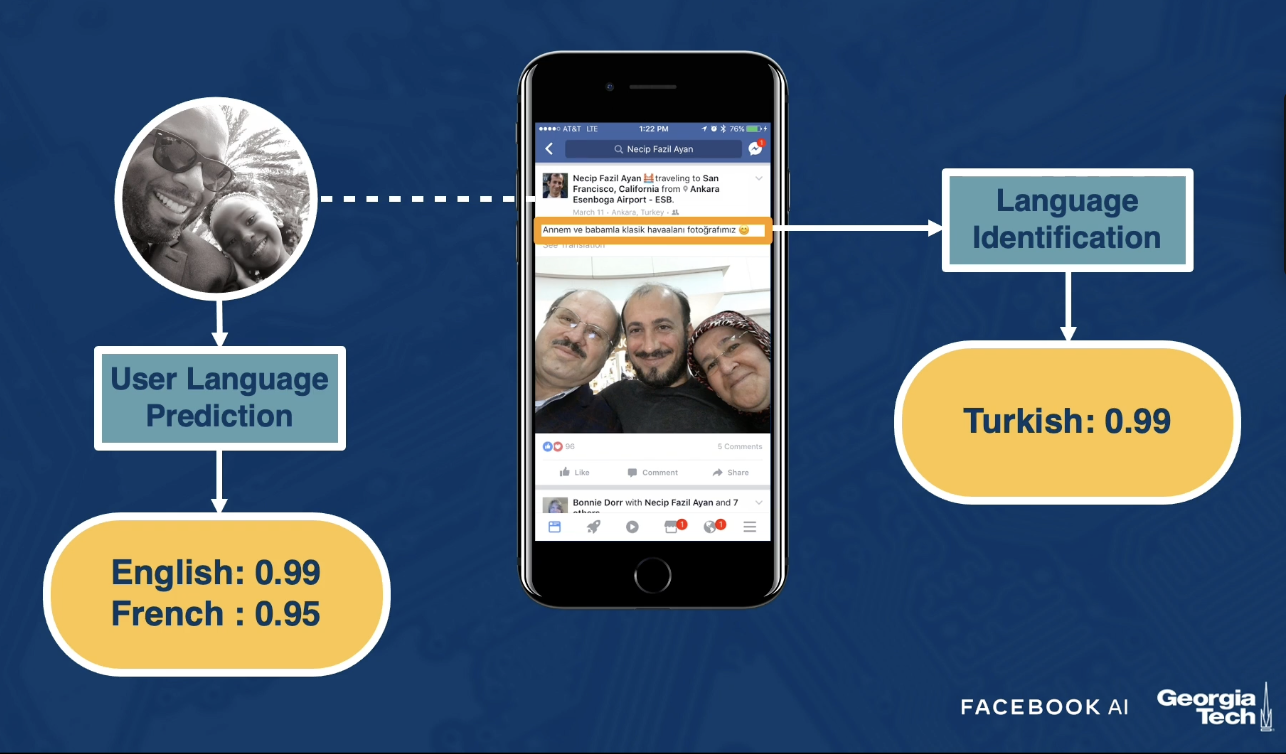
Meta also uses auto-translation in cases where the quality of translation is above a certain threshold.
Challenges + Considerations
Low-Resource Languages
Language translation methods tend to be good for languages with ample training data. But what if our target language has relatively limited data?
Neural machine translation systems have a steeper learning curve with respect to the amount of training data, resulting in worse quality in low-resource settings, but better performance in high-resource settings.
- Six Challenges for Neural Machine Translation (Koehn & Knowles, 2017)
To solve this problem, Meta took the following approach:
- Develop an evaluation set to serve as a benchmark for scoring translations to the low-resource target language.
- Apply transfer learning using existing models for high-resource languages.
Supplemental approaches may also be applied to improve performance. For example, language agnostic sentence representations seek to find a latent multilingual encoding. By training on high-resource languages, the encoder can then be applied to other (low-resource) languages.
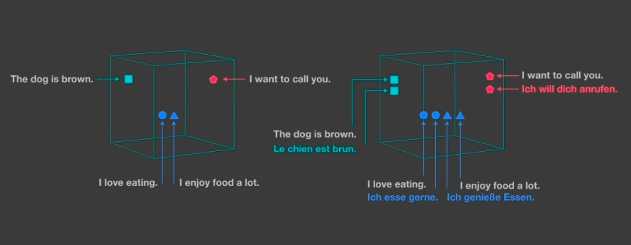
Furthermore, semi-supervised methods applied within backtranslation have been found to improve results.
Translation Quality
We tend to believe translation quality exists on a linear scale. However, this is actually a poor representation - given even a slightly small mistake, we may have a very bad / offensive translation much worse than an alternative with many minor grammatical errors.
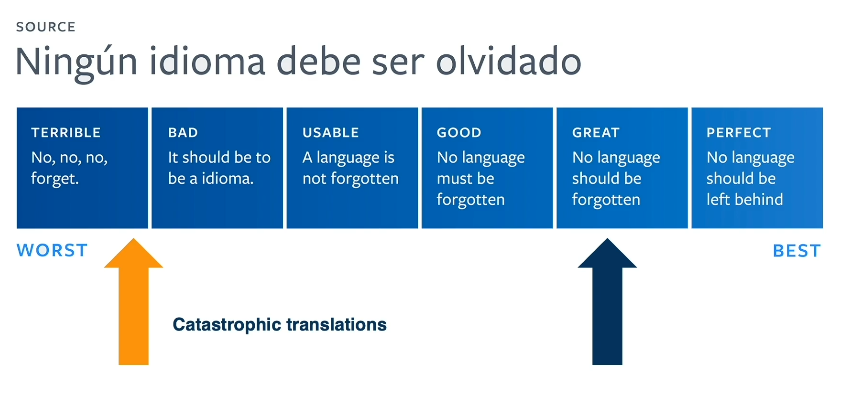
What are some examples of catastrophic translations?
- Bad named entity translation $\rightarrow$ may direct users to incorrect location.
- Incorrect pronouns $\rightarrow$ off-putting user experience.
- False profanities $\rightarrow$ offensive to user.
- Implausible translations $\rightarrow$ nonsensical results.
- Introduction of violent terms $\rightarrow$ may have repercussions depending on the context.
A more practical translation evaluation system might frame evaluation from the user perspective. What are characteristics of a “good” versus “bad” translation, according to the user? Incorporating these components into evaluation may lead to a more robust + trustworthy framework for translation.
Automated Speech Recognition
Overview + Audio Preprocessing
Automated Speech Recognition (ASR) is the process of converting an audio signal containing speech into a transcript of text. Input audio is processed in a number of ways…
- Convert audio into overlapping audio frames of fixed duration (ms).
- We use overlapping frames since audio is a continuous signal (would lose information by discretizing).
- Apply Fourier Transform to audio frames to yield frequency domain representation.
- Calculate Mel Features by applying convolution-based Mel filters.
Given processed features, we can now perform speech recognition.
Approach 1: Modularized ASR
Modularized (Hybrid) ASR decomposes speech recognition into modules by functionality. First, the acoustic model is responsible for classifying audio frames into sound units (phonemes). The acoustic model is trained using a dataset of audio frames, with frame-wise labels for true sound units (provided via an alignment model). The pronunciation model then constructs words from the predicted sound units. Finally, a language model is used to predict the final speech recognition text from the words provided in the previous step.
Approach 2: Non-Modularized ASR
A Non-Modularized ASR system uses a single model for the entire ASR task - given the features produced from audio processing, non-modularized ASR generates the final predicted text.
To understand non-modularized ASR, consider the similar task of machine translation. Machine translation models take a sequence of words in the original language as input, and produce a sequence of words in the target language as output. For this reason, we commonly use sequence-to-sequence (seq2seq) models for machine translation. Neural seq2seq architectures for machine translation typically have the following structure:
- Embedding Layer: used to convert terms into dense vectors, which intend to capture the semantic meaning of the term.
- Encoder: sequentially generates hidden states for each term in the input. Subsequent hidden states incorporate information from previous time steps (in addition to the input term to the current time step).
- Decoder: generates output in target language term-by-term; has access to entire set of hidden states and previous generated terms at each time step.
The Listen-Attend-Spell (LAS) ASR model applies this framework to the task of speech recognition. Instead of terms (words), LAS takes the sequence of audio frames as input, and predicts the final text as a sequence of letters (hence the “spell” in LAS).
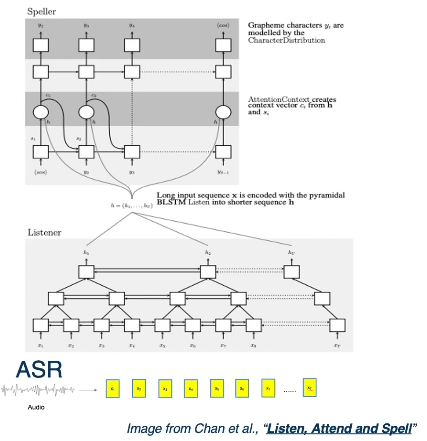
CTC systems are still somewhat problematic since they only use the audio embedding at time step $t$ to generate a prediction. RNN-T systems are perhaps the most optimal choice for streaming, since they utilize the embedding at time step $t$ and text history produced so far $y_{t-1 : 0}$ to predict over output units.
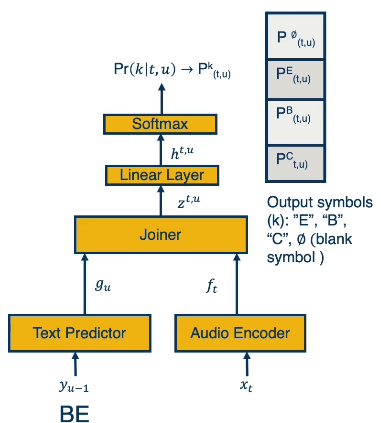
RNN-T Systems: A Closer Look
An RNN-T ASR system has the following components:
- Audio Encoder: encodes sequence of audio features into audio embeddings. Typically implemented as LSTM, bi-directional LSTM, or transformer. Analogous to acoustic model for modular ASR systems.
- Text Predictor: language model which encodes transcript produced so far into text embedding. Typically implemented as LSTM.
- Joiner: combines outputs of encoder and predictor prior to passing through output layer.
Similar to translation, we can generate speech in a greedy fashion by selecting the predicted argmax at each time step, or maintain some set of candidate hypotheses to extend generation down multiple paths. Recall that beam search limits our search space by keeping the $k$ top-scoring candidate hypotheses across the prediction lattice at each time step.
RNN-T Personalization
To implement personalization, we might choose to add a biasing module to the non-modularized ASR network structure. The biasing module is queried for sub-words generated by the decoder (in previous time steps) to determine if any context-specific words should be considered in the current generation.
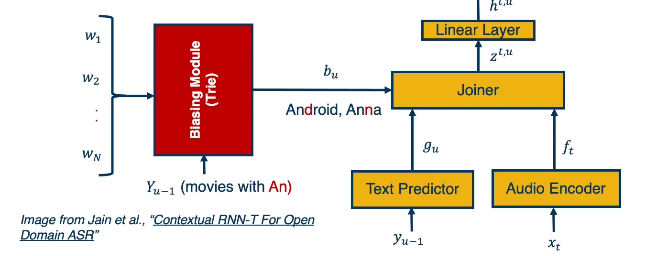
The biasing module is typically used in conjunction with attention to compare the decoder’s current state against the context list. If a match is found, the module extracts a context vector that is combined with the main network’s output.
(all images obtained from Georgia Tech DL course materials)