DL M8: Advanced Computer Vision Architectures
Module 8 of CS 7643 - Deep Learning @ Georgia Tech.
Lesson 8 of CS 7643: Deep Learning @ Georgia Tech.
Introduction
We’ve spent a considerable amount of time setting the framework for computer vision (CV) by considering one of its more basic tasks - image classification. In this lesson, we will extend our view to consider more advanced CV tasks such as image segmentation and object detection.
Image Segmentation
Image Segmentation is an image-to-image problem in which we are interested in generating some class distribution per pixel to separate the image into meaningful components. Semantic Image Segmentation generates a class distribution per pixel, but does not distinguish between instances of a class. In contrast, Instance Segmentation does make this distinction.

Modeling Approach
Image segmentation translates a ($3 \times H \times W)$ input to a $(C \times H \times W)$ output. Here, $C$ refers to the number of classes - our model generates a probability distribution over pixels $(H \times W)$ for each of the $C$ classes.
Fully-connected (FC) layers are problematic for image segmentation since we lose spatial information necessary to represent our image. A Fully-Convolutional Network is one approach to segmentation which completely disregards FC layers. These types of networks are common in image segmentation.
Another strategy for image segmentation is to use an Encoder-Decoder neural architecture as follows:
- Encoder: extracts informative, lower-dimensional features from the input.
- Decoder: re-generates a higher-dimensional output using lower-dimensional features.
In the context of CNNs, decoding might resemble operations such as de-convolution or inverse pooling. For example…
- De-Convolution: each input pixel to decoder is multiplied by all values of kernel, and “stamped” onto the output.
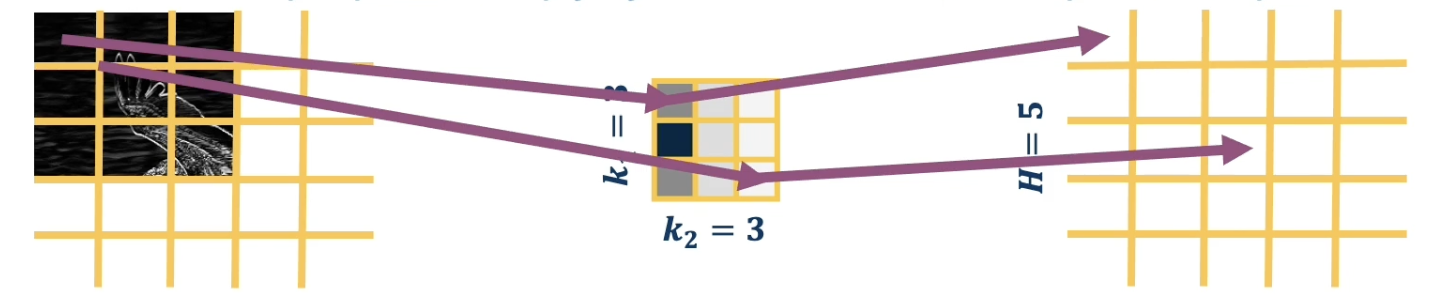
- Inverse Pooling: as part of decoder, make smaller input larger by placing maximum value in same position as encoder.
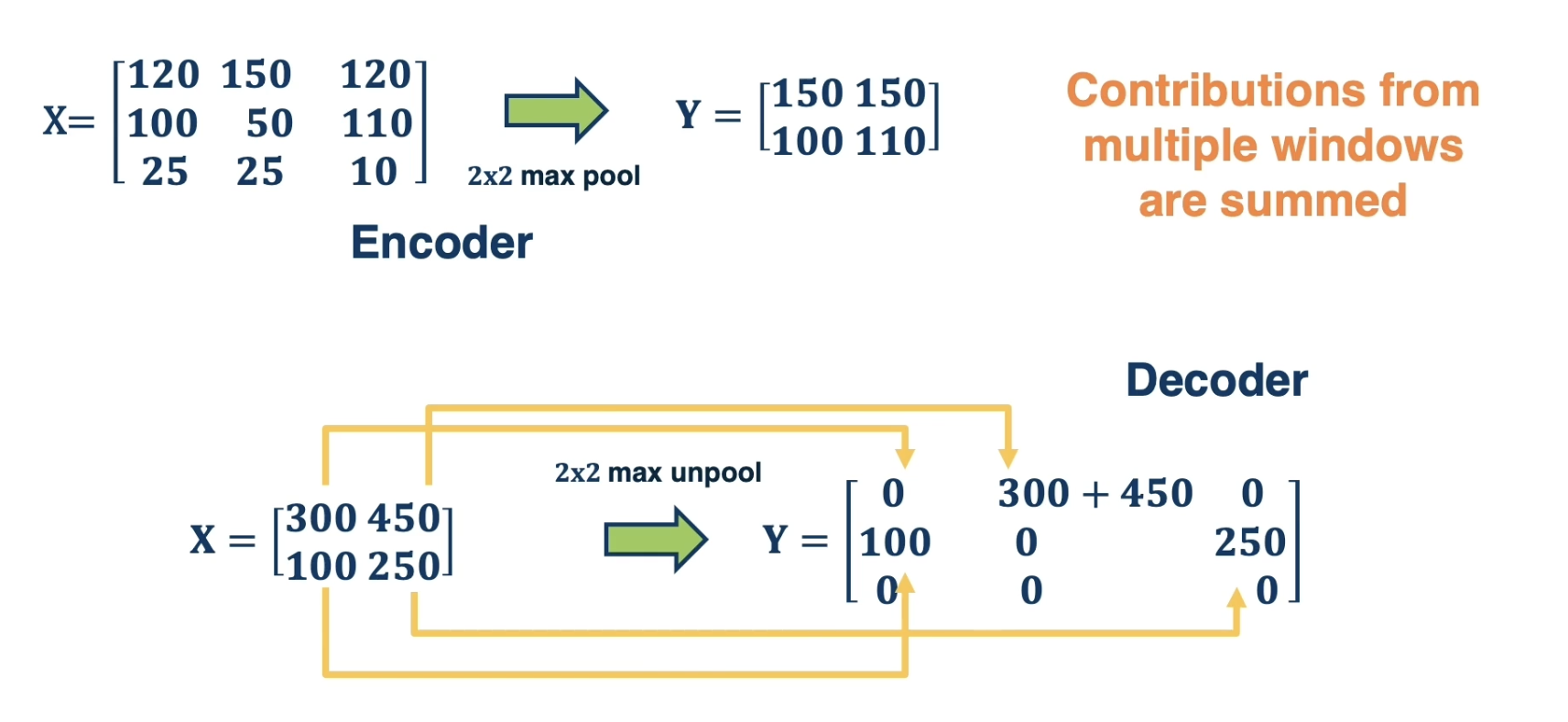
Therefore, our final encoder-decoder structure involves a mirrored structure. The decoder has de-convolution and inverse pooling operations matching those for the encoder.
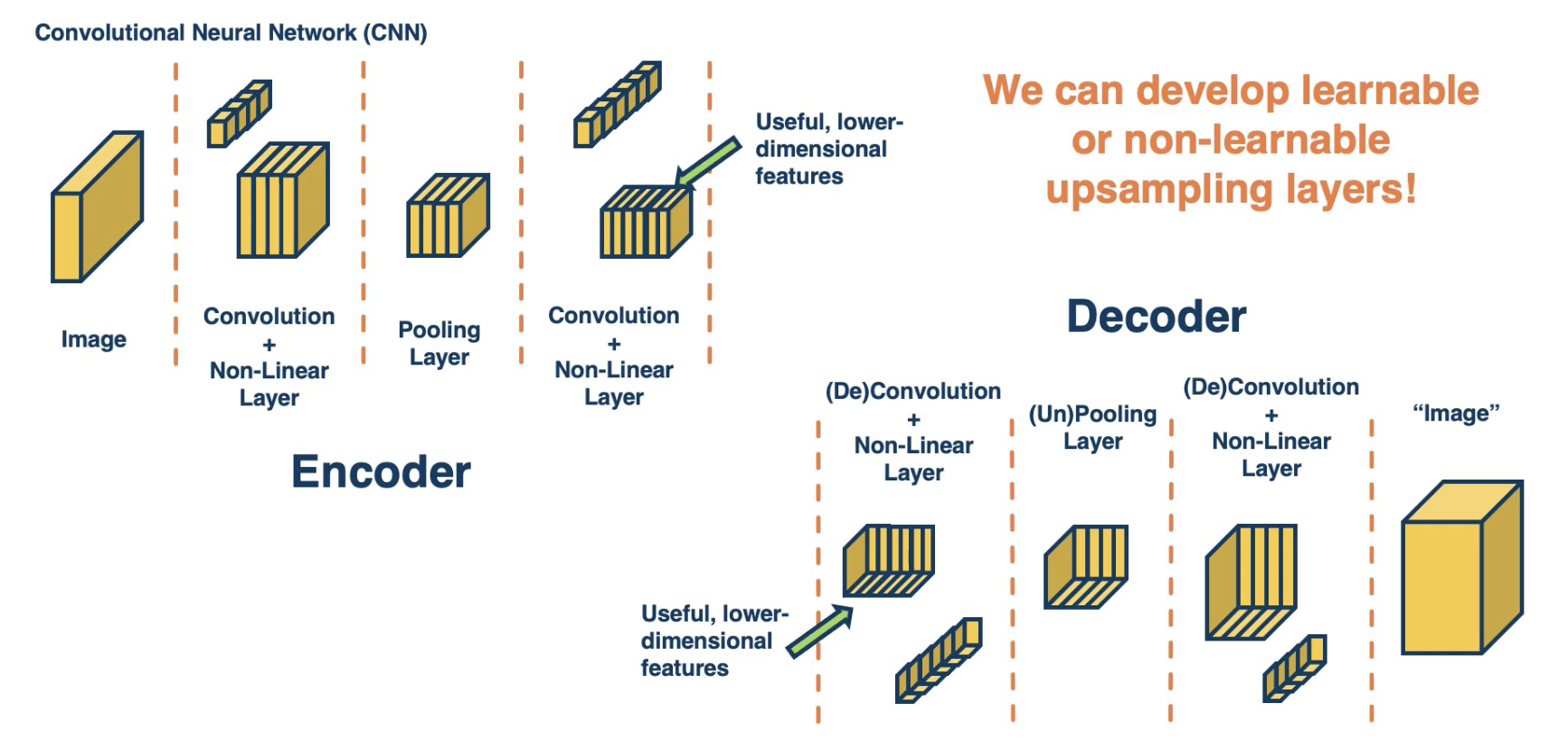
Object Detection
Another type of computer vision task is Object Detection - this represents the problem of generating bounding boxes with a corresponding probability distribution over classes for each box.
Modeling Approach
Single-Stage Object Detectors use a multi-headed architecture to estimate both bounding box and probability distribution from intermediate feature maps. More specifically, given a set of feature maps output from the final convolutional layer, we have two branches:
- Branch 1: predicts four numbers ($x, y, w, h$) to define the bounding box (REGRESSION).
- Branch 2: generates probability distribution over output classes (CLASSIFICATION).
We therefore have a hybrid loss function consisting of mean squared error for the regression component and cross entropy for the classification component. Object detection models are compared using benchmark datasets for object detection such as COCO (Common Objects in Context).
Two-Stage Object Detectors
Two-Stage Object Detectors decompose object detection into two problems:
- Identify regions of interest (ROIs) containing object-like things.
- Classify these regions and refine their bounding boxes.
Region-based Convolutional Neural Networks (R-CNNs) apply the selective search algorithm to extract ROIs, then feed each ROI through a neural network to produce output features. This vanilla approach accomplishes the task, but is quite slow in practice due to sequential ROI processing.
Vanilla ROIs process each ROI separately - this implies computational waste, since ROIs may have overlapping regions that are fed through the same convolutional layers. Fast R-CNN is a variant which improves efficiency by re-using feature map computations across different ROIs. Fast R-CNN also uses ROI pooling to transform convolutional outputs to a fixed size (since the size of convolutional output is dependent on ROI size, which may be variable).
Faster R-CNN is another R-CNN variant which uses a neural network called a Region Proposal Network (RPN) to identify ROIs, as opposed to a non-learning algorithm such as selective search.
(all images obtained from Georgia Tech DL course materials)