GIOS M6: Thread Performance
Module 6 of CS 6200 - Graduate Introduction to Operating Systems @ Georgia Tech.
Considerations
Performance Case Study
We can evaluate thread performance from one of many perspectives. For example, let’s compare the performance of two multi-threading architectures: the boss-worker and pipeline patterns.
- Problem Description:
- Given $\rightarrow$ 6 total threads, 11 toy orders
- Boss-Worker $\rightarrow$ 120 ms to process single order
- Pipeline $\rightarrow$ 20 ms to process single pipeline stage
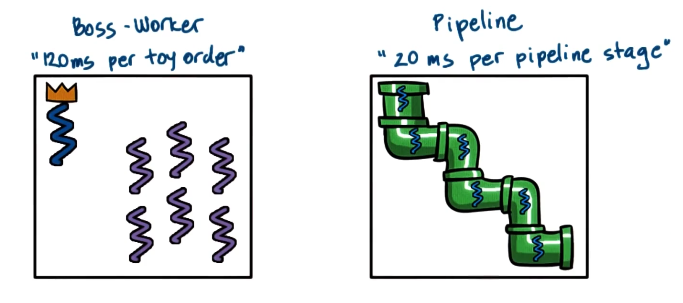
(image should show 5 worker threads, not 6)
- Metric 1: Execution Time
- Boss-Worker $\rightarrow$ $\text{ceil}(\frac{11}{5}) \times 120 = 360 \text{ms}$
- Pipeline $\rightarrow$ $20 \times 6 + 10 \times 20 = 320 \text{ms}$
- Metric 2: Average Time per Order
- Boss-Worker $\rightarrow$ $\frac{120 \times 5 + 240 \times 5 + 360}{11} \sim 196 \text{ms}$
- Pipeline $\rightarrow$ $\frac{120 + 140 + 160 + \ldots + 320}{11} = 220 \text{ms}$
This case illustrates that our multi-threading design choices are highly important on the context of the problem. For example, are we more interested in processing more orders given time, or enhancing user experience by reducing wait times per order?
Metrics
In the context of multi-threading, we are typically interested in one of the following performance metrics:
- Throughput: process completion rate; typically average number of processes completed in a given amount of time (ex: $\frac{\text{process}}{\text{second}}$).
- Response Time (Latency): length of time from initial request to response.
- Utilization: percentage of total time in which CPU was executing process (as opposed to context switching or blocking).
In analysis systems, our metrics should be measurable and/or quantifiable. The metric should be used to evaluate some aspect of our system’s behavior.
Evaluating Thread Utility
Can we demonstrate that threads are useful in the context of any performance metric(s)? Recall that concurrency can be provided via multiple threads, or multiple processes. We will compare these implementations for a simple web server described as follows.
Web Server Overview
As part of our simple web server, we have a few key steps…
- Client/browser sends request.
- Web server accepts request.
- Server performs processing steps.
- Server responds to client by sending file.
… where server processing groups together a sequence of many operations.
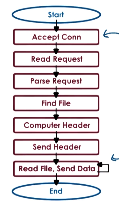
We can implement a multi-process (MP) web server by having multiple instances of the “processing steps” portion of the workflow. The cons with this approach include 1) high memory usage (on a per-process basis), 2) costly context switching, and 3) expensive inter-process communication requirements.
Alternatively, we could develop the web server as a multi-threaded (MT) application by having each thread perform the sequence of processing steps in parallel. The MT approach implies 1) a shared address space, 2) shared state, and 3) cheaper context switching. There are cons in terms of 1) program complexity and 2) synchronization considerations.
Event-Driven Model
We can also make alternative program design choices instead of writing our program as a sequence of operations. The Event-Driven Model relies on events and an event dispatcher - given a certain event, the event dispatcher will call the appropriate handler to execute pre-specified code for the event. For a single-threaded single process program, this implies execution will jump to the start of the event handler.
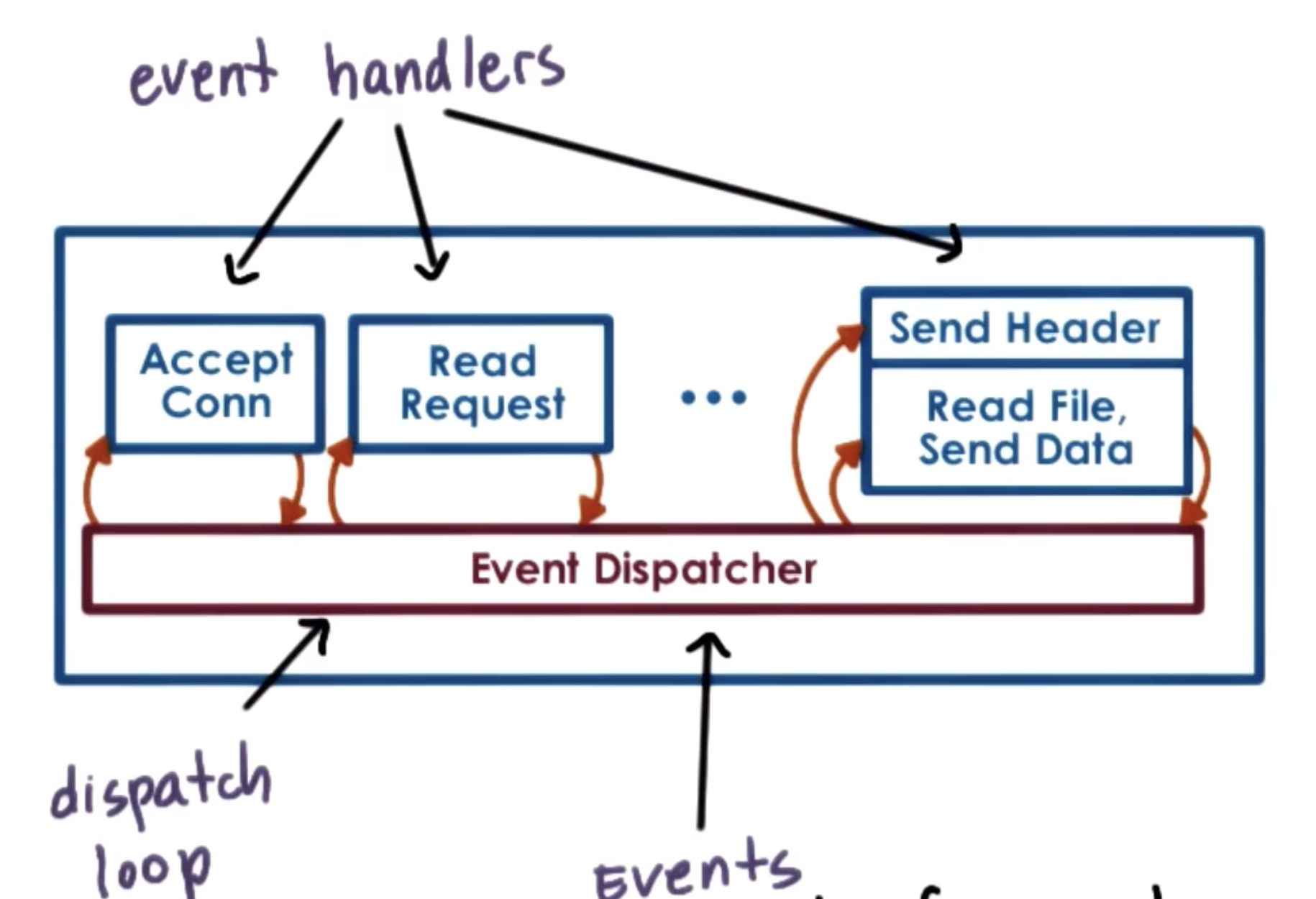
How can we apply concurrency within the event-driven model? Unlike the MP or MT approaches, event-driven models specifically avoid dedicated process / thread assignment (e.g., assigning each request to an execution context). Instead, the event-driven approach interleaves requests within the same execution context.
- Event Loop: server runs a loop that waits for events (e.g., new connection or file input).
- Non-Blocking I/O: when a request hits a slow operation (such as I/O), the server initiates the operation but does not wait. It instead switches to process the next request int he queue.
Why is this beneficial over the MP / MT approaches?
- We have the benefits of a single thread (single address space, flow of control, smaller memory requirement, no synchronization).
- There is no context switching. Consider the case where an incoming request is mapped to a thread in the MT approach - we must switch from the main execution context to the new thread.
Furthermore, asynchronous system calls for slow events such as I/O operations can improve process efficiency. As part of an asynchronous operation, the process makes a system call and supplies any additional data structures to hold results. The process then continues while a kernel thread / device performs the operation, and eventually returns requested information to the caller once complete. In the case where asynch is not supported, we can manage this task ourselves using MP or MT with respect to blocking operations. Asymmetric Multi-[Process\Threaded] Event-Driven Model (AMPED/AMTED) exemplifies this sort of implementation.
Example Web Servers
Flash is an event-driven web server which follows the AMPED model. It uses helper processes to perform blocking I/O tasks, and event dispatchers + handlers for the primary functionality.
In contrast, the popular Apache web server combines MP and MT architecture into a single application. The core of Apache is a basic server skeleton; additional per-functionality modules are added on an as-needed basis. Apache uses multiple processes, with each process following a boss-worker thread pattern with dynamic thread pool.
Flash Paper + Experimental Methodology
The Flash Paper (1999) introduced AMPED architecture via Flash, and evaluated it relative to many other web server types:
- MP: multi-process web server, with each process as a single thread.
- MT: multi-threaded web server following boss-worker pattern.
- Single Process Event-Driven (SPED).
- Zeus: SPED with two processes.
- Apache web server.
The authors defined trace and synthetic workloads to evaluate the web servers in terms of bandwidth and connection rate (as a function of file size). They made the following observations:
- When data is in cache (implying no I/O blocking)…
- SPED » AMPED Flash $\rightarrow$ Flash tests for memory presence.
- SPED and AMPED Flash » MP / MT $\rightarrow$ additional overhead from context switching / synchronization.
- When the workload is disk-bound…
- AMPED Flash » SPED $\rightarrow$ SPED blocks b/c no synchronous I/O.
- AMPED Flash » MP / MT $\rightarrow$ more memory efficient + less context switching.
(all images obtained from Georgia Tech GIOS course materials)