ML M13: Feature Selection
Module 13 of CS 7641 - Machine Learning @ Georgia Tech. Lesson 3 of Unsupervised Learning Series.
What is Feature Selection?
Definition
Feature Selection refers to the process of subsetting a set of features for use in subsequent analytic methods. We typically perform feature selection as part of preprocessing for other machine learning methods (e.g., supervised learning, clustering, etc.). This is done for two primary reasons:
- Interpretability and Insight $\rightarrow$ by limiting features to a smaller subset, we provide manual attention to the “most important” features. It would be unreasonable to directly interpret even $500$ features!
- Curse of Dimensionality $\rightarrow$ in machine learning tasks, adding more features exponentially increases the amount of data required for generalization. Therefore, using a smaller set of features may actually make our learning problem easier!
Time Complexity
Given an initial feature set of $N$ features, we are interested in finding a subset of size $M$. If we know $M$ in advance, we must compare over $N$ choose $M$ possible subsets. We don’t typically have a desired subset size, meaning we have $2^N - 1$ possible subsets!
Feature selection therefore has exponential time complexity and is considered a nondeterministic polynomial (NP) hard problem.
Feature Selection Approaches
Feature selection methods may be broadly grouped into two main categories.
Filtering Methods
Feature selection by Filtering works by performing feature selection prior to a learning algorithm. Evaluation is bundled into the feature selection search algorithm, and is not intertwined with the learning process.
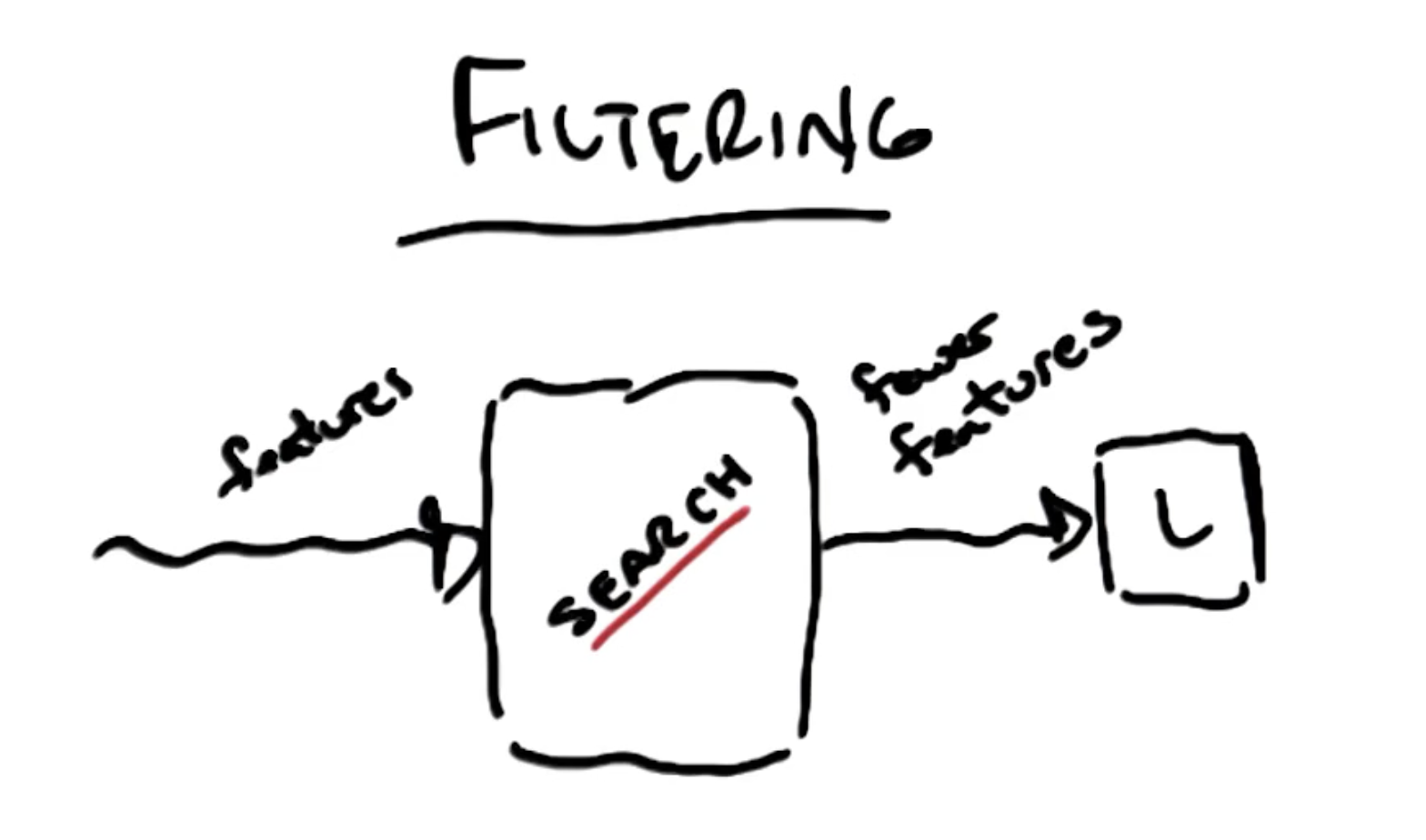
In general, any filtering feature selection algorithm works as follows:
- Define function to evaluate usefulness of feature subset (e.g., information gain, non-dependent features, statistical test, etc.).
- Apply function to each possible subset, and keep top $M$ subsets.
Wrapping Methods
Conversely, Wrapping performs feature selection in conjunction with a learning algorithm. Subsets are evaluated by fitting the learning algorithm, implying feature selection and learning are an intertwined process.
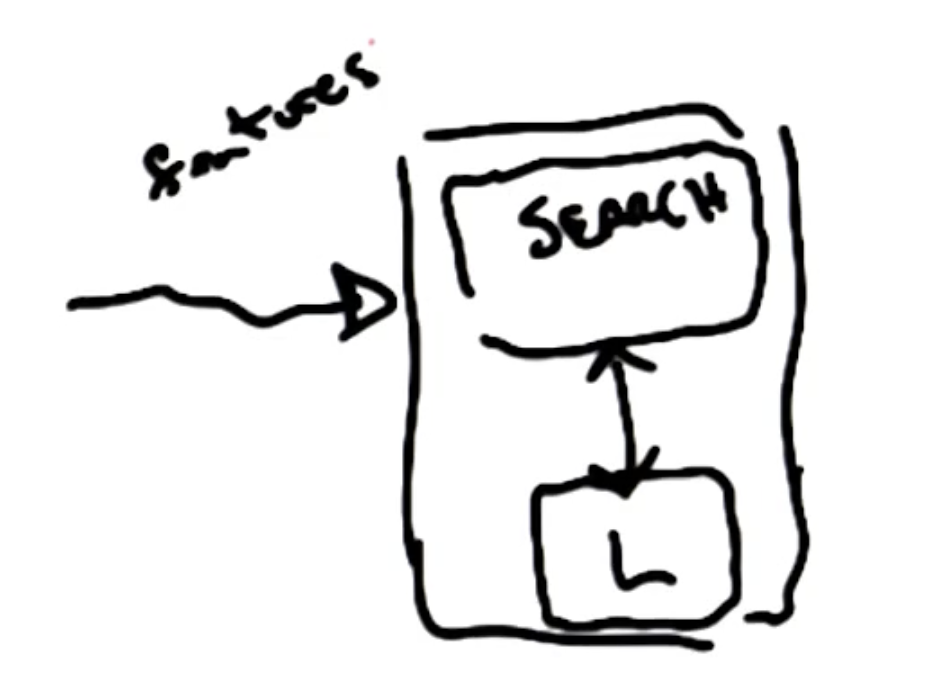
Examples of wrapping feature selection include forward selection and backward selection! Forward selection works by iteratively adding the “best” feature to a subset until reaching some evaluation threshold. Conversely, backward selection involves starting with the full feature set and iteratively removing the “worst” (least informative) feature.
Comparison of Properties
Filtering tends to be faster than wrapping because it does not use the learning process as part of subset search. This comes with the downside of feature isolation, meaning we evaluate candidate feature subsets outside of the context of the end-goal learning algorithm.
Although wrapping is much slower, it takes into account model bias to determine the best feature subset. Wrapping therefore makes more sense conceptually, but can come at a very high cost depending on the end-goal learning algorithm (e.g., deep neural network)!
In the context of feature selection, Relevance refers to the degree of association / utility a feature has with the target (e.g., evaluation).
$\mathbf{x}_i$ is strongly relevant if removing it degrades the Bayes Optimal Classifier (B.O.C.).
$\mathbf{x_i}$ is weakly relevant if it is not strongly relevant, and $\exists$ some subset of features $S$ such that adding $\mathbf{x}_i$ to $S$ improves the B.O.C.
$\mathbf{x}_i$ is irrelevant otherwise.
Relevance measures effect on the B.O.C., whereas usefulness measures effect on a particular predictor. Relevance is related to information, whereas usefulness has an impact on error / learning.
(all images obtained from Georgia Tech ML course materials)