NLP M10: Machine Reading
Module 10 of CS 7650 - Natural Language Processing @ Georgia Tech.
Introduction
Machine Reading is the process of extracting factual knowledge from unstructured text in order to place it into a structured knowledge base.
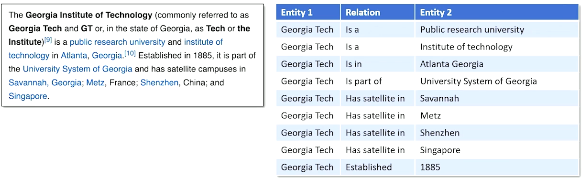
Information Extraction
The key concept behind machine reading is Information Extraction:
- Closed Information Extraction: search for a predefined fixed set of relation types.
- might be problematic as information changes over time, or if we have to specify too many relation types.
- Open Information Extraction: extract structured knowledge from unstructured text without knowing the entities / relations in advance.
Framing the ML Problem
How do we frame information extraction as a machine learning problem? Consider the case of supervised learning; we would have to 1) manually label some corpus with relevance to our relation categories (multinomial classification), and 2) derive some method for extracting information from relevant portions of text. Distant supervision is a modification on this approach which automatically derives labels using an existing knowledge base. However, this does not resolve all of our issues with manual labeling.
Unsupervised Learning is much more appropriate, enabling us to avoid the process of manual labeling altogether. For the remainder of this lesson, we assume that we are interested in open information extraction (which tends to be more useful in the case of NLP). In order to present open information extraction as an unsupervised learning problem, we must define some preliminary concepts.
Syntax Parsing
Syntax is the arrangement of words and phrases to create well-formed sentences in a language. Note that semantics arise from syntax; meaning changes depending on the implications of structural rules. Also, even syntactically well-formed sentences can have ambiguous meaning…
1
"Jane wrote a book on the moon."
When discussing syntax, we should be familiar with the core parts of speech - categories to which any word is assigned in accordance with its syntactic functions. Here are the major parts of speech relative to the English language.
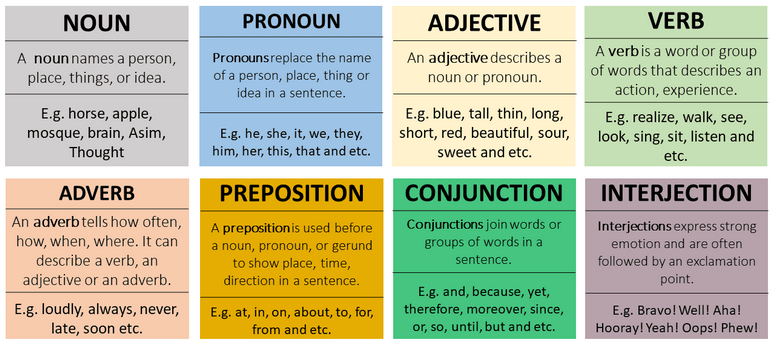
We perform Speech Tagging - assigning a part of speech tag to each word in a sentence - in order to incorporate information on parts of speech into our problem. This typically involves a probabilistic approach (e.g., Bayesian network).
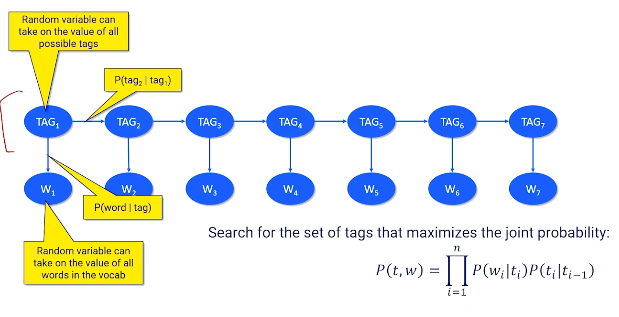
- $\Pr(w | t)$: words are a probabilistic emission from tags; given a tag, we are more likely to see certain words than others.
- $\Pr(t_2|t_1)$: the order of tags is often predictable; given a tag, we are more likely to see certain tags follow as opposed to others.
But our data only contains the words, and not the actual tags. How can we determine the tags in our document? We can use dynamic programming in combination with maximum likelihood to efficiently compute the most probable sequence of latent values (tags) that would result in our observed word emission.
Dependency Parsing
We can take any particular sentence, perform parts of speech tagging, then construct a dependency graph detailing the relationships of words within the sentence.
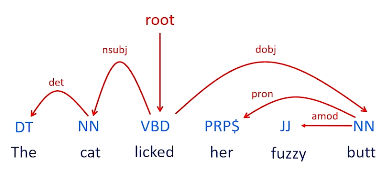
Shift-reduce parsing is used to build a dependency graph from the bottom up. This method relies on tag relationships to sequentially construct the dependency graph, where tag relationships may be learned via some supervised learning problem.
Methods for Open Information Extraction
As part of open information extraction, we are typically interested in translating unstructured text (sentences) into <subject, relation, object> triplets. This is accomplished by…
1) Recognizing named entities within the input text (identifies subject and object). 2) Walking through the relevant portion of the dependency graph (identifies relation).
These triplets may be used to populate a knowledge base, where the knowledge base stores all different ways entities are related to one another. Knowledge bases are particularly useful for question answering.
Note that pure neural approaches have not been as robust as dependency parsing for creating structured knowledge from unstructured text. However, language model-based methods are improving at question answering capabilities and may overtake dependency model parsing.
Frames and Events
Fact-based knowledge acquisition can help answer who-what-when-where questions. However, “why” questions tend to be much more difficult to answer.
What are Frames and Events?
Events are descriptions of changes in the state of the world, whether actual or implied. They are semantically-rich constructs that bring additional knowledge which might not be readily apparent from a given sentence.
A Frame is a system of related concepts such that understanding one concept requires understanding all other concepts / relationships (e.g., “sell” implies a more complicated relationship involving seller, recipient, possession, etc.). Systems such as FrameNet hold a linguistic dictionary of frames, and are typically manually curated.
How do they Relate to the “Why” Question?
Events and event frames can be particularly useful for answering questions regarding change. For example, what was necessary for that change to happen that wasn’t explicitly stated? The state-tracking and conceptual context offered by events and frames (respectively) is much more informative than a simple surface-level analysis of text.
(all images obtained from Georgia Tech NLP course materials)