NLP M11: Open Domain Question Answering (Meta)
Module 11 of CS 7650 - Natural Language Processing @ Georgia Tech.
Introduction
Question Answering refers to the task of generating natural language to answer a query question. Open Domain implies the question may involve one of many potential topics. Therefore, an open domain question answering system typically relies on general ontologies and world knowledge in order to generate meaningful answers.
There are a few primary forms of question answering problems in NLP:
- Multiple Choice: question with accompanying set of possible answers. Typically presented alongside a short body of text (ex: read the passage before answering).
- Span Selection: answer to question must be span of text present in the provided passage.
- Cloze: entities in a passage of text are masked, and system must answer questions involving these entities.
- Generative Question Answering: generate answer based on summary snippet as context. Very similar to query-based summarization.
Implementation
How can we design a question answering system? The Classical Approach to question answering uses a logical series of steps:
- Detailed question analysis.
- Multi-stage answer generation.
- filtering of question and answer texts.
- Scoring of answer candidates w.r.t. questions.
- Ranking answer candidates.
However, modern state-of-the-art methods utilize concepts from Information Retrieval as part of their design.
Retrieval Reader
Two-Stage Reader Retrieval in question answering refers to the process of 1) gathering relevant documents, and 2) reading the documents to generate + rank answers. More formally, this process consists of the information retrieval and reading comprehension stages.
Our problem can be framed as follows:
- INPUT: set of descriptive documents and a query question.
- OUTPUT: answer extracted from the descriptive documents.
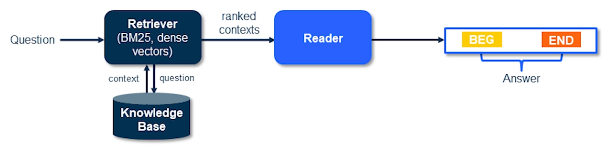
In the most vanilla setting, we use TF-IDF to retrieve documents relative to the query question. This sort of retriever does not require training, which enables easier scaling to new domains.
The reader stage is a bit more involved - our reader must parse the retrieved documents and extract a relevant answer. Most readers function by jointly encoding the question + documents into some latent space, then generating answers using this joint encoding. For example, BERT representations can be created by concatenating the question and document with some separator token in between.
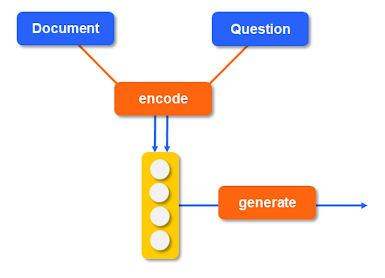
We can train our reader using Reading Comprehension datasets for span selection, which consist of question-passage-answer triplets. In the case where our passage is not clearly defined, we can use distant supervision to convert question-answer pairs to question-passage-answer triplets. Note that every passage returns a candidate answer - we may therefore be interested in re-ranking to select candidate answers supported by multiple evidences.
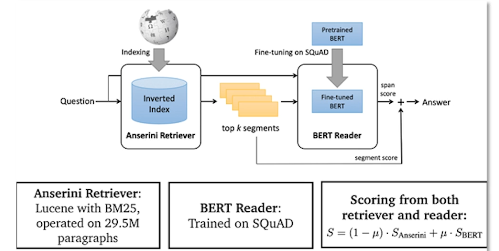
BERTserini is an example implementation of an end-to-end open domain question answering system which follows this sort of framework.
Multi-Hop Reasoning
So far, we’ve framed question answering in terms of a singular question and related body of documents. But what if our single question decomposes into a series of interconnected questions? The answers cannot be retrieved in one shot, so we must have multiple hops to generate our final response.
Multi-Hop Reasoning preserves context across hops to process a series of inputs. In multi-hop question answering, the distinction between “multi” and “single” hop is dependent on the reference body of text as opposed to being a property of input question. For example, we may require multiple components of information as part of an input question:
In which city was Facebook first launched?
- Answer 1: Zuckerberg attended Harvard University.
- Answer 2: Harvard University is in Cambridge, Massachusetts.
Most existing solutions for multi-hop retrieval use Wikipedia hyperlinks to reduce the search space. Some approaches explicitly construct sequential queries, where the retrieved results from one query are used to generate a new reformulated query.
ML Considerations
Training Methods
As part of Multi-Passage Training, we use passages that DO NOT contain our answer of interest in combination with the passage containing our answer. This has been found to improve the performance of models. We train a passage re-ranker to determine which passages contain vs. don’t contain our answer.
Dense Representations
Recall that we can represent terms to perform information retrieval in one of two major ways:
- Sparse Representation: one-hot representations of tokens $\rightarrow$ sentences $\rightarrow$ passages.
- Dense Representation: use embeddings to generate token representation in latent space (non-sparse = not many 0’s), then form representations of sentences / passages as desired.
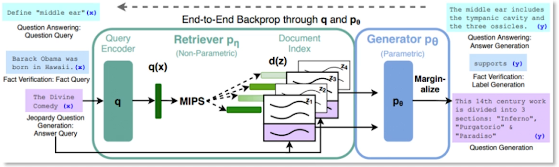
Whereas Sparse Retrieval is based on simple term matching, Dense Retrieval makes use of latent semantic encoding to retrieve relevant documents. We can apply methods such as maximum inner product search (MIPS) to speed up the retrieval process.
Retrieval Augmented Generation (RAG) uses dense retrieval (via a pre-trained retriever) in combination with generation (via a pre-trained seq2seq generator). The results of the retriever are ranked by MIPS, then fed into the generator to produce the final text.
Datasets and Benchmarks
Curated datasets such as TriviaQA, SearchQA, and Quasar-T provide query questions and supporting text evidence for use in evaluating question answering systems. There are also datasets explicitly devoted to multi-hop reasoning, such as HotpotQA and FEVER.
(all images obtained from Georgia Tech NLP course materials)