NLP M13: Private AI (Meta)
Module 13 of CS 7650 - Natural Language Processing @ Georgia Tech.
What is Private AI?
Private AI is concerned with maintaining proper privacy and data protection standards during the model training process.
Ideally, our model should learn the high-level trends present in our training data. However, there is potential for the model to “memorize” specific values, even if the model is generalizing well + hasn’t overfit our data. If these values are sensitive, this can be a big problem! For example, Large Language Models (LLMs) such as GPT-2 have been shown to directly reproduce contact information appearing only once (!) in the training set.
The primary goal of Private AI is to avoid memorization of sensitive information in the training data so that it cannot be directly reproduced during inference. How can we do this? One simple approach is to anonymize records:
- Directly remove any sensitive columns.
- Perform bucketing to reduce granularity. ex: age = 53 $\rightarrow$ age <60
Still, there are many assumptions + issues that come along with this approach. We must use more advanced techniques in order to more effectively guarantee privacy.
Advanced Private AI Techniques
Differential Privacy
Consider the following situation: we have input data $D$, a learning algorithm $M$, and model parameter results $R$. We train the learning algorithm on two datasets $D_1$ and $D_2$, where the only difference between the datasets is that $D_2$ excludes a certain instance.
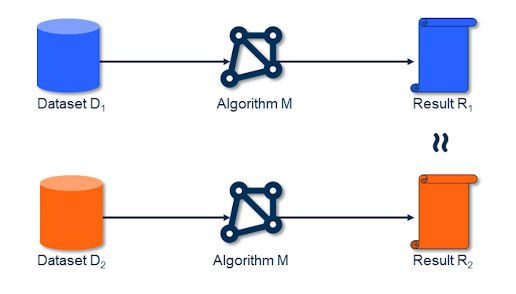
It is reasonable to conclude that our training procedure preserves privacy with regards to the excluded instance if $R_1$ is approximately equivalent to $R_2$. This is the core idea of Differential Privacy. Note that privacy is coming from the training mechanism as opposed to any direct changes to the dataset.
Stochastic Gradient Descent and Differential Privacy
Recall that Stochastic Gradient Descent (SGD) is the optimization procedure we use to train neural networks. How can we incorporate differential privacy into stochastic gradient descent?
DP-SGD works by adding noise proportional to the magnitude of the largest per-instance gradient, thereby guaranteeing the signal of any individual instance cannot be distinguished from noise. Although functional, this is problematic in the context of unbounded gradients - if we have some massive per-instance gradient, we will have to add a massive amount of noise. Therefore, DP-SGD is typically implemented with gradient clipping to ensure noise addition is reasonable + not too detrimental to the learning process.
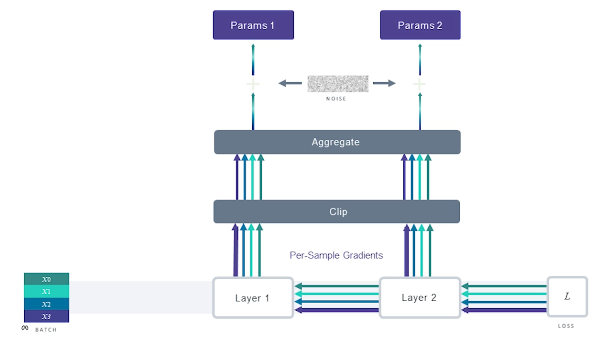
It’s worth noting that other machine learning training parameters also impact privacy:
- Epochs: increasing number of epochs tends to decrease privacy. This is because increased training duration results in a representation closer to “memorizing” the training data.
- Batch Size: increasing batch size tends to increase privacy. Larger batches result in more consistent (less variable) noise / clipping application.
- Noise / Clipping: more aggressive noising / clipping strategies tend to result in better privacy.
DP-SGD comes along with a few limitations. First and foremost, model learning is partially handicapped by noise addition. We must strike an effective balance between noise addition (privacy) and model performance. Additionally, DP-SGD requires more memory than SGD since we must store the per-instance gradients at each update step. Finally, certain neural network module types (ex: Batch Normalization) are incompatible with DP-SGD.
Future Directions
Private AI is still an emerging + evolving field. There are many open questions that require more comprehensive answers:
- How can we learn effectively with differential privacy? Are there certain architectures, activation functions, and/or DP-SGD variants which perform better in this context?
- Can we better understand attack strategies to better deal with “guaranteeing” privacy? For example, is the general approach of differential privacy “overkill” relative to privacy attacks?
(all images obtained from Georgia Tech NLP course materials)