NLP M9: Applications Summarization (Meta)
Module 9 of CS 7650 - Natural Language Processing @ Georgia Tech.
What is Summarization?
The goal of Summarization is to faithfully present a compact representation of a larger body of information. A good summarization system has the following characteristics:
- Faithful: stays true to the facts presented in the original information.
- Relevant: captures the most informative part(s) of the original information.
- Coherent: has sentences that are natural and tell a smooth, complete story.
Types of Summarization
An Extractive Summarization selects some of the original sentences / sub-sentences as the final summary. The result is guaranteed to be faithful, but may be redundant or lack coherence.
On the other hand, an Abstractive Summary uses the original information to generate a summary from scratch. This approach often results in a coherent product, but faithfulness may be an issue.
Summarization Metrics
Given a summarization, how can we evaluate its quality? Generative tasks such as translation and summarization are relatively hard to evaluate, given the space of acceptable responses is very large. In the context of summarization, we have additional problems: faithfulness is difficult to measure and relevance can be subjective.
BLEU
The Bilingual Evaluation Understudy (BLEU) is a evaluation score which measures the similarity between a generated body of text and corresponding ground truth reference. It works by computing the product of the Brevity Penalty (which penalizes short translations not containing relevant text from the reference) and the geometric mean of BLEU$_n$ scores for $n$-grams between one and four. BLEU was originally designed for machine translation, but is also applicable to summarization.
ROUGE
ROUGE is the most common metric used in summarization. ROUGE applies precision and recall to $n$-gram matching. More specifically…
- $\text{ROUGE}_n ~ \text{PRECISION:} ~~ \frac{\text{n overlapping n-grams}}{\text{n total n-grams in predicted summary}}$
- $\text{ROUGE}_n ~ \text{RECALL:} ~~ \frac{\text{n overlapping n-grams}}{\text{n total n-grams in true summary}}$
ROUGE-1 and ROUGE-2 are the most common metrics, along with ROUGE-$L$ (where $L$ is the length of the longest common subsequence between prediction and truth). Furthermore, results are typically summarized as F1-score, which is the harmonic mean of precision and recall.
Other Metrics
The biggest problem with ROUGE is that we are evaluating direct token matches, as opposed to matching based on semantics. Additionally, we can have multiple valid summaries, instead of the single reference summary used in the ROUGE calculation.
BERT-score is calculated using a pre-trained BERT to compare the contextual cosine similarity between embedded tokens in the prediction to embedded tokens in the true summary. Similarly, BART-score uses a pre-trained BART (sequence-to-sequence) model to estimate the probability of the prediction given the original document.
- BERT: Bidirectional Encoder Representations from Transformers.
- BART: Bidirectional and Auto-Regressive Transformers.
NLP Summarization Methods
Prior to the wave of neural networks applied to NLP problems, there were various classical models applied to the problem of summarization. In this module, we skip over classical models and start with state-of-the-art, which began with neural models applied to abstractive sentence summarization in 2015.
Neural Abstractive Summarization
Early neural summarization approaches (2015) utilized a Seq2seq architecture, similar to the task of machine translation. As part of the seq2seq implementation, successful approaches made use of the decoder as a language generation model, and utilized attention to attend to the encoded input sequence. This type of architecture is trained in an end-to-end fashion; the encoder is provided with the original document to be summarized, and the decoder is expected to generate our final predicted summarization. Similar to other Seq2seq models, neural abstractive models train via teacher forcing to ensure the model relative to good intermediate sequence outputs.
One key problem with the Seq2seq approach is that the model has too much freedom. We therefore need a ton of data to train the model to generate proper summarizations.
Pointer-Generator Networks
The Pointer-Generator Network (2017) built on Seq2seq architecture by estimating the probability of both generating and copying at each time step. This component elegantly blends abstractive and extractive summarization via an architectural bias.
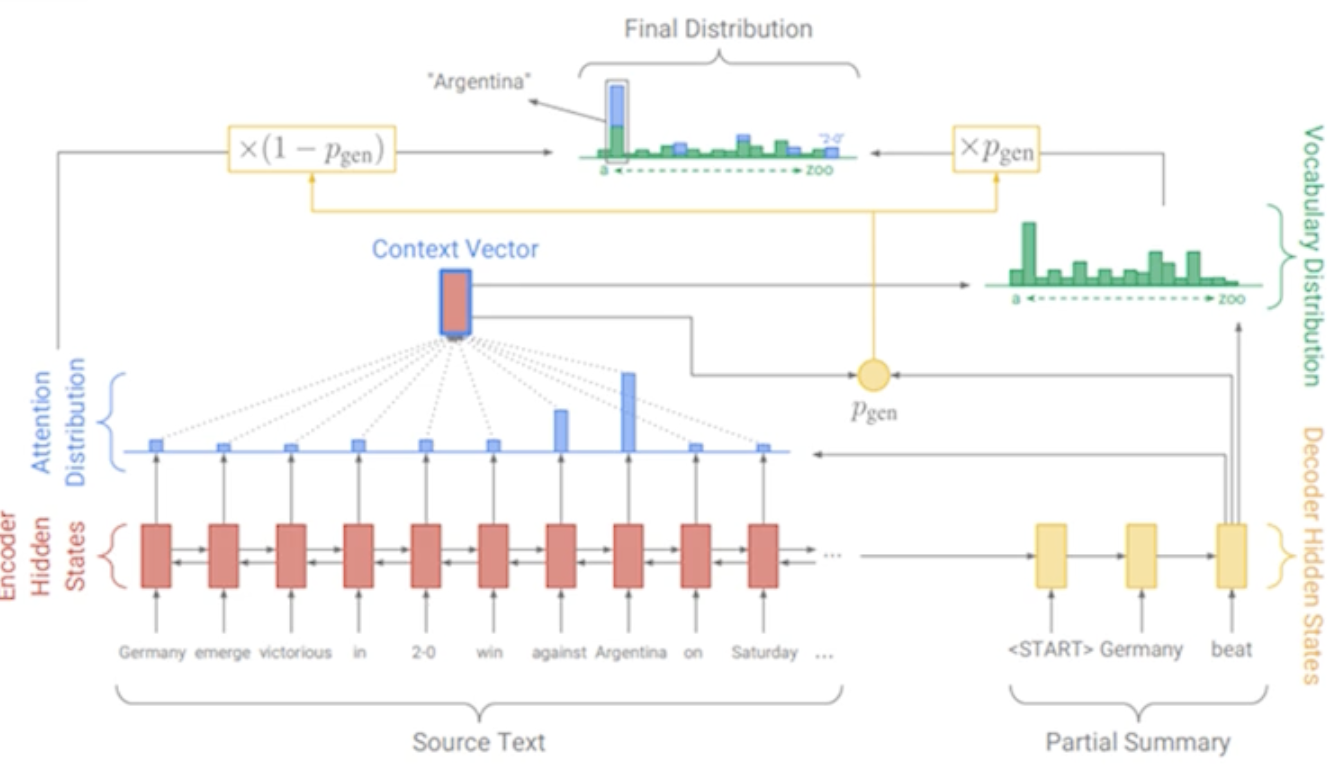
- Attention defines the probability distribution over extracted terms.
- Vocabulary distribution defines the probability distribution over generated terms.
The final distribution is a combination between the copy distribution (attention) and generation distribution (vocabulary).
BertSum
Pre-trained encoders such as BERT and RoBERTa have been applied to summarization by framing the problem as a sentence classification task. BertSum (2019) is a specific application of BERT to extractive summarization. It is trained using a set of labeled sentences, with sentences corresponding to binary inclusion in the final summary. In other words, the job of BertSum is to predict whether a sentence should be included in the final summary.
The primary drawback of this approach is that sentences are scored independently. This might result in redundancies or conflicts in the final summary.
Pre-Trained Models
Pre-trained models such as GPT and BART provide strong language models for text generation. These models can be tailored to summarization via fine-tuning or some form of N-Shot Learning, where n-shot learning refers to the number of examples we provide to a pre-trained model via the prompt at inference time.
Hallucination
In the context of summarization, Hallucination refers to infidelity to original context - the model changes or adds facts from the original document that may be incorrect. This is the biggest issue when using a pre-trained language model.
Automated techniques to evaluate model hallucination have been introduced (including BART-score), but this is still an area of ongoing research.
(all images obtained from Georgia Tech NLP course materials)